On February 16, 2024, OpenAI announced on a social media platform the grand introduction of its new text-to-video model – Sora.
This model can generate videos up to 60 seconds in length, and during this process, it can switch camera angles on its own, and even deliver close-ups. Below are the translated video prompts and the “works” directly produced by Sora based on the original English prompts.
Prompt:
Source: Open AI
A stylish woman walks down a Tokyo street filled with warm glowing neon and animated citysignage. She wears a black eather jacket, a ong red dress, and black boots, and carries a black purseShe wears sunglasses and red lipstick. She walks confidently and casually. The street is damp.
Prompt:
Source: Open AI
3D animation of a small, round, fluffy creature with bigexpressive eyes explores a vibrant, enchanted forest.The creature, a whimsical blend of a rabbit and a squirrel,has soft blue fur and a bushy, striped tail.It hops along asparkling stream,its eyes wide with wonder. The forest isalive with magical elements: flowers that glow and changecolors, trees with leaves in shades of purple and silver,and small floating lights that resemble fireflies. The creaturestops to interact playfully with a group of tiny, fairy-like beingsdancing around a mushroom rinq.The creature looks up inawe at a large, glowing tree that seems to be the heartof the forest
At first glance, you might think these videos were produced by a professional film crew or an animation studio. Within the OpenAI community, there are also many users who share this sentiment, expressing concerns that Sora might take away animators’ livelihoods.
🎨 Sora looks to bring both creative unlocks and new panic-inducing capabilities for bad actors.
Sora generates videos by leveraging its advanced text-to-video model. It interprets written prompts and translates them into dynamic, detailed visual content. This process involves understanding the text, conceptualizing a visual representation, and then rendering these concepts into a cohesive video data. Sora’s abilities include changing camera angles, incorporating close-ups, and producing videos that closely align with the provided descriptions.
The concern that Sora might take away human jobs is a significant one. While Sora and similar technologies demonstrate impressive capabilities, they also raise ethical and societal questions. The use of such advanced AI can indeed impact professions in filmmaking, animation, and related creative fields. However, it’s important to consider that while AI can automate certain tasks, it also opens up new opportunities for human creativity and innovation. It can serve as a tool that enhances human work rather than outright replacing it.
As with any disruptive technology, there’s a period of adjustment where industries and professions adapt to incorporate new methods and tools. Rather than taking away jobs wholesale, Sora might change the nature of work in creative industries, requiring professionals to acquire new skills and adapt to working alongside AI. This evolution could lead to a new era of collaboration between humans and AI, with each bringing their unique strengths to the table.
Furthermore, regarding the potential misuse of Sora-like technologies for creating deepfakes or false evidence, it is crucial for regulatory bodies, technology companies, and civil society to work together to establish guidelines and detection tools. Ethical use policies and educational initiatives can help mitigate risks and ensure these technologies are used responsibly and for the betterment of society.
How does Sora generate videos?
Since the second half of 2022, applications like Midjourney and Stable Diffusion have been able to generate images corresponding to text prompts. In September 2023, the combination of GPT-4.0 and DALL·E 3 has also enabled us to generate and modify images in a conversational manner.
AI-generated videos are not a new concept either. Before the release of Sora, there were already several video-generating AIs, such as Pika, Stable Video, RunwayML, and so on. However, compared to Sora, other models produce videos of shorter duration and are significantly less capable in aspects like camera movement and scene transitions.
Source: X post by Gabor Cselle
Sora generates videos through a process described by OpenAI in a technical report, which reveals that “Sora is a diffusion model.” This means Sora employs a type of generative model that gradually transforms random noise into a structured image or sequence of images (i.e., a video) based on the input text prompts.
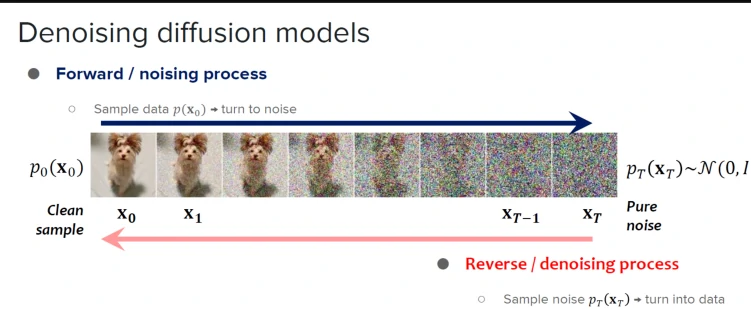
Diffusion models work in two phases: the forward phase, where an original image is gradually added with noise until it becomes pure noise; and the reverse phase, where the model learns to reverse this process, starting from noise and step-by-step removing noise based on the conditioning information (e.g., text prompts) to create the final image or video.
For video generation, Sora extends this concept across time to produce sequences of images that look like a continuously flowing video. It interprets the text prompt to understand the scene, actions, and even camera movements described, and then, using a vast dataset it’s been trained on, Sora can generate sophisticated videos that correspond with the text. This includes features like camera angle changes and close-ups, as mentioned. Essentially, Sora uses the diffusion process to convert narrative text into a visual story, frame by frame, creating a video that visually represents the described scenes and actions.
“Sora is a diffusion model.” Source: OpenAI official website
Exactly, to grasp the idea of a diffusion model without delving into its complex details, let’s picture a simplified example.
Imagine we have a photo of a dog. By incrementally adding noise to this photo, we make it progressively blurrier, step by step, until it’s nothing but a collection of random noise.
“In the process of adding and removing noise,” according to reference [3]
Initially, noise is incrementally added to an image — in this scenario, a dog’s photo — step by step, making it progressively more indistinct until it transforms into pure noise. This is the forward process, where the image’s information gets obscured gradually.
The second phase, or the reverse process, involves meticulously removing the noise from this now randomized noise image. The model has been trained to understand what the original content (e.g., a dog) should look like based on the descriptions or other forms of input that guide the reconstruction process. Therefore, by reversing the noise addition, it fabricates an image from the noise that aligns with the intended outcome, such as regenerating the dog’s photo or creating entirely new imagery based on textual prompts.
This duality of adding and then removing noise underpins the model’s ability to generate or reconstruct images and videos from textual descriptions, guiding the transformation from randomness to structured visual content.
If we reverse this process, we can take a collection of random, chaotic noise and step by step remove the noise, restoring it to the target image. The key to a diffusion model is learning how to reverse the noise addition.
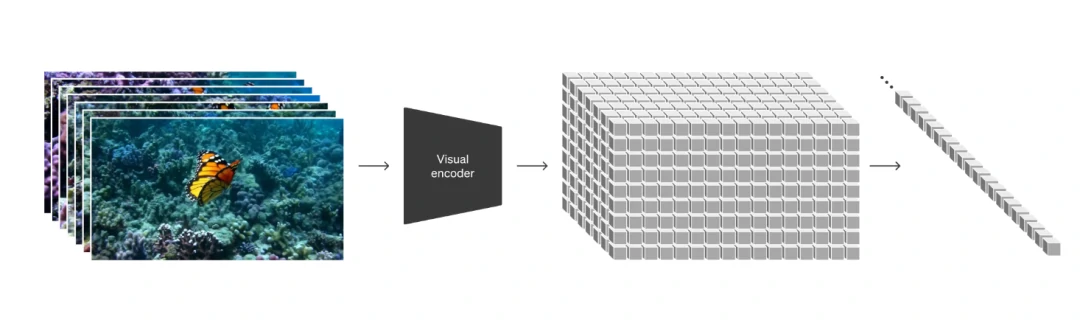
Of course, diffusion models are not only capable of generating images but can also be used to generate videos. For example, the technical report on Sora mentions that OpenAI transformed video data to directly train the model, allowing Sora to generate videos directly based on prompt words.
Sora transforms video data for processing
Sora’s powerful video creation capabilities
According to OpenAI, Sora “inherits” GPT’s understanding of text, enabling it to generate high-quality images and videos based on prompt words. Moreover, it can extend videos forward or backward. For example, it can continue from the same video start to extend into different endings, or it can proceed from different starts and converge towards the same ending.
“These three video beginnings ultimately converge to the same ending.” Source: OpenAI official website
Additionally, Sora is not only capable of generating videos based on text prompts but can also directly input images or videos for editing and adjustment.
For instance, it can make a car driving on a regular road look more “cyberpunk.”
Source: OpenAI official website
Furthermore, Sora has demonstrated some capabilities previously unanticipated, such as its ability to follow an object with the camera and, while changing the camera’s angle during movement, still maintain a coherent and complete surrounding scene.
Source: Open AI
“Powerful Sora: Unveiling Its Limitations”
Although Sora has demonstrated impressive capabilities, it is not yet perfect at this stage.
In its technical report, it is acknowledged that videos generated by Sora at the current stage have some flaws. For example, in a video clip of “archaeologists excavating a plastic chair,” the plastic chair obviously defies the laws of physics to some extent.
Source: Open AI
Additionally, the process of a glass breaking is not very “scientific” either — the liquid starts to spill out before the glass actually shatters.
Source: Open AI
It may struggle to accurately simulate the physical principles of complex scenes and might not fully grasp causal relationships. The model may also confuse spatial details in prompts, such as mixing up left and right, and it may struggle to precisely describe events that unfold over time, such as following a specific camera trajectory.
“Is Sora Safe and Could It Replace Humans? Unpacking the Future of AI”
In recent days, videos generated by Sora have swept through many people’s social circles, eliciting admiration for Sora’s capabilities, but also sparking concerns that center around two main issues.
The first concern is about the prowess of Sora in generating videos. If such technology were to be used for creating fake content, wouldn’t that be terrifying? How will we be able to discern if the videos we see in the future are real or fabricated?
The second concern primarily arises from professionals within the video industry. If models like Sora become widespread, does that mean industry practitioners might lose their livelihoods?
Regarding the issue of safety, OpenAI has indeed considered the potential security concerns that Sora could bring. Currently, Sora is only accessible to a limited number of individuals, and it won’t be made available to the general public until there is assurance that it won’t be used for malicious purposes.
As for whether Sora might replace human video creators, the answer is that it’s possible. For instance, in January this year, The Hollywood Reporter conducted a survey among 300 leaders in the entertainment industry. Three-quarters of the respondents indicated that AI would reduce job opportunities in the future, with around 200,000 positions potentially being affected over the next three years. Sora’s impressive capabilities could exacerbate this impact.
Conclusion
From another perspective, the emergence of new technologies, while potentially posing threats, also brings about new opportunities.
Including Sora, video-generating AIs are merely tools, and the source of creativity for videos still requires human input. Sora might be able to help humans produce videos more efficiently and also enable every individual to have the opportunity to create their own inventive videos. This perspective emphasizes the collaborative potential between AI technologies like Sora and human creativity, suggesting a future where AI augments and amplifies human capabilities rather than simply replacing them.